|
. |
|
|
|
|
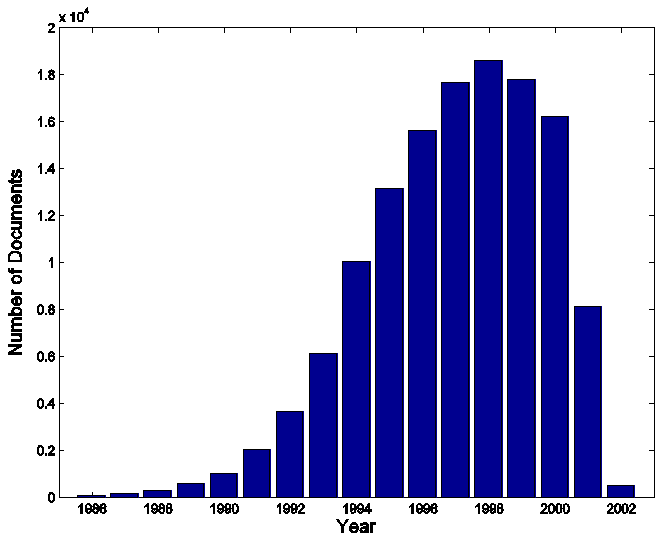
Our collection of CiteSeer abstracts contains D=162,489 abstracts with K=85,465 authors. For each abstract, only the first 5000 characters were available. We preprocessed the text by removing all punctuation and removed stop words. This led to a V=30,799 vocabulary size, and a total of 11,685,514 word tokens. There is inevitably some noise in data of this form given that many of the fields (paper title, author names, year, abstract) were extracted automatically by CiteSeer from PDF or postscript or similar files. We chose the simple convention of identifying authors by their first initial and second name, e.g., A_Einstein, given that multiple first initials or fully spelled first names were only available for a relatively small fraction of papers. This means of course that for some very common names (e.g., J_Wang or J_Smith) there will be multiple actual individuals represented by a single name in the model. This is a known limitation of working with this type of data. There are algorithmic techniques that could be used to automatically resolve these identity problems---however, in this paper, we don't pursue these options and instead work with the first-initial/last-name representation of individual authors. Of the original 162,489 CiteSeer abstracts in our data set, the year of publication ranged from 1990 to 2002 has been estimated by CiteSeer for 130,545 of these abstracts. The Figure below shows breakdown by year for this set. We see the steady (and well-known) increase in the number of online documents through the 1990's. From 1999 through 2002, however, the number of documents drops off sharply each year. This is due to fact that it is easier to determine the date of publication of older documents, e.g., by using citations to these documents---the graph reflects the natural latency in the citation process.
|